
Після нещодавнього витоку документів антимонопольного позову проти Google у нас є унікальна можливість вивчити алгоритми Google . Деякі з цих алгоритмів були вже відомі , але цікавою є внутрішня інформація, якою ми ніколи не ділилися.
Ми розглянемо, як ці технології обробляють наші пошуки, і визначимо результати, які ми побачимо. У цьому аналізі я прагну надати чітке та детальне уявлення про складні системи, що стоять за кожним пошуком Google.
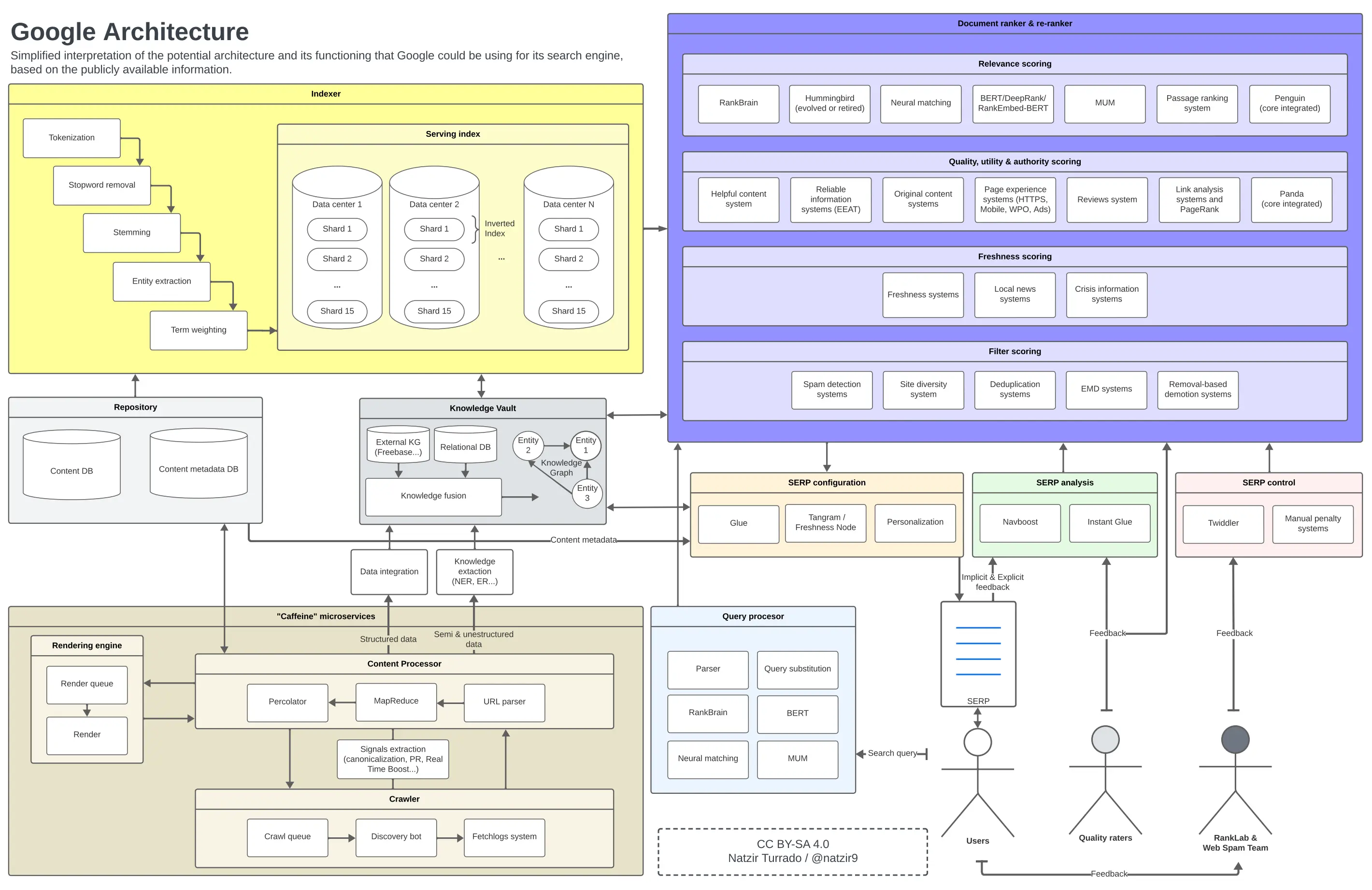
Крім того, я спробую представити архітектуру Google на діаграмі з урахуванням нових відкриттів.
Розкрито алгоритми Google
Спочатку ми зосередимося на вилученні всіх алгоритмів, згаданих у 2 документах. Перший стосується свідчень Панду Наяка (віце-президента Alphabet), а другий — про Свідчення спростування професора Дугласа В. Оарда щодо думок експерта Google, професора Едварда А. Фокса, у його звіті від 3 червня 2022 року. Цей останній документ обговорював відомий і суперечливий «Звіт Fox», де Google маніпулював експериментальними даними, щоб спробувати продемонструвати, що дані користувачів не такі важливі для них.
Я спробую пояснити кожен алгоритм на основі офіційної інформації, якщо така є, а потім розмістю інформацію, отриману під час випробування, на зображенні.

Navboost
Це ключовий фактор для Google і один із найважливіших факторів. Це також стало відомо під час витоку «Project Veritas» у 2019 році, оскільки Пол Хаар додав це до свого резюме

Navboost збирає дані про те, як користувачі взаємодіють із результатами пошуку, зокрема, натискаючи різні запити. Ця система зводить клацання в таблицю та використовує алгоритми, які навчаються на створених людьми оцінках якості, щоб покращити рейтинг результатів. Ідея полягає в тому, що якщо результат часто вибирають (і позитивно оцінюють) для конкретного запиту, він, ймовірно, повинен мати вищий рейтинг. Цікаво , що багато років тому Google експериментував із видаленням Navboost і виявив, що результати погіршилися.

RankBrain
RankBrain , запущений у 2015 році, є системою штучного інтелекту та машинного навчання Google, яка є важливою для обробки результатів пошуку. Завдяки машинному навчанню він постійно покращує свою здатність розуміти мову та наміри, що стоять за пошуком, і особливо ефективний у тлумаченні неоднозначних або складних запитів. Кажуть, що він став третім найважливішим фактором у рейтингу Google після вмісту та посилань. Він використовує тензорний процесор (TPU) , щоб значно підвищити його можливості обробки та енергоефективність.

Я зробив висновок, що QBST і Term Weighting є компонентами RankBrain. Тому я включаю їх сюди.
QBST (Query Based Salient Terms) зосереджується на найважливіших термінах у запиті та пов’язаних документах, використовуючи цю інформацію для впливу на ранжирування результатів. Це означає, що пошукова система може швидко розпізнати найважливіші аспекти запиту користувача та визначити пріоритетність відповідних результатів. Наприклад, це особливо корисно для неоднозначних або складних запитів.
У документі свідчень QBST згадується в контексті обмежень BERT. Особлива згадка полягає в тому, що « BERT не включає великі системи запам’ятовування, такі як navboost, QBST тощо ». Це означає, що хоча BERT є високоефективним у розумінні та обробці природної мови, він має певні обмеження, одним із яких є його здатність працювати з або замінити великомасштабні системи запам’ятовування, такі як QBST.

Зважування термінів регулює відносну важливість окремих термінів у запиті на основі того, як користувачі взаємодіють із результатами пошуку. Це допомагає визначити, наскільки релевантними є певні терміни в контексті запиту. Це зважування також ефективно обробляє терміни, які є дуже поширеними або дуже рідкісними в базі даних пошукової системи, таким чином збалансовуючи результати.

DeepRank
Іде на крок далі в розумінні природної мови, дозволяючи пошуковій системі краще розуміти наміри та контекст запитів. Це досягається завдяки BERT ; насправді DeepRank є внутрішньою назвою BERT . Завдяки попередньому тренуванню на великому обсязі даних документів і коригування за допомогою зворотного зв’язку від клацань і людських оцінок DeepRank може точно налаштувати результати пошуку, щоб вони були більш інтуїтивно зрозумілими та релевантними тому, що користувачі фактично шукають.

RankEmbed
RankEmbed, ймовірно, зосереджується на завданні вбудовування відповідних функцій для ранжирування. Хоча в документах немає конкретних деталей про його функції та можливості, ми можемо зробити висновок, що це система глибокого навчання, розроблена для вдосконалення процесу класифікації пошуку Google.
RankEmbed-BERT
RankEmbed-BERT є розширеною версією RankEmbed, яка інтегрує алгоритм і структуру BERT. Цю інтеграцію було здійснено, щоб значно покращити можливості розуміння мови RankEmbed. Його ефективність може знизитися, якщо не перекваліфікуватися з останніми даними. Для свого навчання він використовує лише невелику частину трафіку, що означає, що немає необхідності використовувати всі доступні дані.
RankEmbed-BERT разом з іншими моделями глибокого навчання, такими як RankBrain і DeepRank, сприяє остаточному рейтингу в пошуковій системі Google, але працюватиме після початкового отримання результатів (переранжування) . Він навчається на даних кліків і запитів і точно налаштовується з використанням даних від людей-оцінювачів (IS), а навчання є дорожчим з обчислювальної точки зору, ніж моделі прямого зв’язку, такі як RankBrain.

МАМА
Він приблизно в 1000 разів потужніший за BERT і являє собою значний прогрес у пошуку Google. Запущений у червні 2021 року, він не тільки розуміє 75 мов, але також є мультимодальним, тобто може інтерпретувати та обробляти інформацію в різних форматах. Ця мультимодальна здатність дозволяє MUM пропонувати більш вичерпні та контекстуальні відповіді, зменшуючи потребу в багаторазовому пошуку для отримання детальної інформації. Однак його використання є дуже вибірковим через високі обчислювальні вимоги.

Танграм і клей
Усі ці системи працюють разом у рамках Tangram , який відповідає за збірку SERP з даними з Glue . Йдеться не лише про ранжування результатів, а про їхнє впорядкування у спосіб, який буде корисним і доступним для користувачів, враховуючи такі елементи, як каруселі зображень, прямі відповіді та інші нетекстові елементи.

Нарешті, Freshness Node і Instant Glue забезпечують актуальність результатів, надаючи більшої ваги нещодавній інформації, що особливо важливо під час пошуку новин або поточних подій.

Під час судового розгляду вони посилаються на атаку в Ніцці, де основна мета запиту змінилася в день атаки, що призвело до того, що Instant Glue приховав загальні зображення в Tangram і натомість рекламував релевантні новини та фотографії з Ніцци («приємно» картинки» проти «гарні картинки»):

З усім цим Google об’єднає ці алгоритми, щоб:
- Зрозуміти запит : розшифровка наміру слів і фраз, які користувачі вводять у рядок пошуку.
- Визначення релевантності: ранжування результатів на основі відповідності вмісту запиту, використовуючи сигнали минулих взаємодій і оцінки якості.
- Пріоритет свіжості : забезпечення того, щоб найсвіжіша та найрелевантніша інформація піднімалася в рейтингу, коли це важливо.
- Персоналізація результатів : адаптація результатів пошуку не лише до запиту, але й до контексту користувача, наприклад його місцезнаходження та пристрою, який він використовує. Навряд чи існує більше персоналізації, ніж це .
З усього, що ми бачили досі, я вважаю, що Tangram , Glue і RankEmbed-BERT є єдиними новинками, які просочилися на сьогодні.
Як ми бачили, ці алгоритми живляться різними показниками, які ми зараз розберемо, знову ж таки, витягаючи інформацію з випробування.
Показники, які використовує Google для оцінки якості пошуку
У цьому розділі ми знову зосередимося на спростуванні свідчень професора Дугласа В. Оарда та включимо інформацію з попереднього витоку, «Project Veritas».
На одному зі слайдів було показано, що Google використовує наступні показники для розробки та коригування факторів, які враховує його алгоритм під час ранжування результатів пошуку, і для моніторингу того, як зміни в алгоритмі впливають на якість результатів пошуку. Мета полягає в тому, щоб спробувати зафіксувати намір користувача за допомогою них.
1. Оцінка IS
Оцінювачі відіграють вирішальну роль у розробці та вдосконаленні пошукових продуктів Google. Завдяки їхній роботі генерується показник, відомий як « оцінка IS » (оцінка інформаційної задоволеності в діапазоні від 0 до 100), отримана на основі оцінок оцінювачів і використовується як основний показник якості в Google.
Він оцінюється анонімно, коли оцінювачі не знають, чи тестують вони Google чи Bing, і використовується для порівняння продуктивності Google із основним конкурентом.
Ці показники IS не лише відображають сприйняту якість, але також використовуються для навчання різних моделей у пошуковій системі Google, включаючи алгоритми класифікації, такі як RankBrain і RankEmbed BERT.
Згідно з документами, станом на 2021 рік вони використовують IS4. IS4 вважається наближеною корисністю для користувача, і її слід розглядати як таку. Його описують як, можливо, найважливішу метрику ранжирування , але вони підкреслюють, що це наближення та схильність до помилок, які ми обговоримо пізніше.

Також згадується похідна від цього показника, IS4@5 .
Метрика IS4@5 використовується Google для вимірювання якості результатів пошуку, зосереджуючись особливо на перших п’яти позиціях. Цей показник включає як спеціальні функції пошуку, такі як OneBoxes (відомі як «сині посилання»). Існує варіант цього показника під назвою IS4@5 web , який зосереджується виключно на оцінці перших п’яти веб-результатів, виключаючи інші елементи, наприклад рекламу в результатах пошуку.

Хоча IS4@5 корисний для швидкої оцінки якості та релевантності найпопулярніших результатів пошуку, його сфера застосування обмежена. Він не охоплює всі аспекти якості пошуку, зокрема пропускаючи такі елементи, як реклама в результатах. Таким чином, показник забезпечує часткове уявлення про якість пошуку. Для повної та точної оцінки якості результатів пошуку Google необхідно розглянути ширший діапазон показників і факторів, подібно до того, як загальний стан здоров’я оцінюється за різними показниками, а не лише за вагою.
Обмеження людських оцінювачів
Оцінювачі стикаються з кількома проблемами, такими як розуміння технічних запитів або судження про популярність продуктів або інтерпретації запитів. Крім того, такі мовні моделі, як MUM, можуть розуміти мову та глобальні знання так само, як люди-оцінювачі , створюючи як можливості, так і проблеми для майбутнього оцінювання релевантності.
Незважаючи на їхню важливість, їх погляди суттєво відрізняються від поглядів реальних користувачів . Оцінювачам може не вистачати конкретних знань або попереднього досвіду, який користувачі можуть мати щодо теми запиту, що потенційно може вплинути на їх оцінку релевантності та якості результатів пошуку.
З витоку документів 2018 і 2021 років я зміг скласти список усіх помилок, які Google розпізнає у своїх внутрішніх презентаціях.
- Тимчасові невідповідності : розбіжності можуть виникати через те, що запити, оцінки та документи можуть бути різного часу, що призводить до оцінок, які не точно відображають поточну релевантність документів.
- Повторне використання оцінок : практика повторного використання оцінок для швидкої оцінки та контролю над витратами може призвести до оцінок, які не відповідають поточній актуальності чи актуальності вмісту.
- Розуміння технічних запитів : Оцінювачі можуть не розуміти технічні запити, що призводить до труднощів в оцінці відповідності спеціалізованих або нішевих тем.
- Оцінка популярності : оцінювачам важко оцінити популярність інтерпретацій конкурентних запитів або конкуруючих продуктів, що може вплинути на точність їхніх оцінок.
- Різноманітність оцінювачів : відсутність різноманітності серед оцінювачів у деяких місцях і той факт, що всі вони дорослі, не відображає різноманітності бази користувачів Google, яка включає неповнолітніх.
- Контент, створений користувачами . Оцінювачі, як правило, жорстко ставляться до контенту, створеного користувачами, що може призвести до недооцінки його цінності та актуальності, незважаючи на те, що він корисний і релевантний.
- Навчання вузла свіжості : вони сигналізують про проблему з налаштуванням моделей свіжості через відсутність адекватних міток навчання. Людські оцінювачі часто не приділяють достатньої уваги аспекту свіжості релевантності або бракує тимчасового контексту для запиту. Це призводить до недооцінки останніх результатів для запитів, які шукають новизни. Існуюча утиліта Tangram, заснована на IS і використовувана для навчання релевантності та інших кривих оцінки, страждала від тієї ж проблеми. Через обмеження людських міток, криві оцінки Freshness Node були скориговані вручну після його першого випуску.
Я щиро вірю, що люди-оцінювачі відповідальні за ефективне функціонування «Паразитної SEO», про що нарешті звернув увагу Денні Салліван і поділився в цьому твіті:

Якщо ми подивимося на зміни в останніх інструкціях з якості, ми побачимо, як вони нарешті відкоригували визначення показників задоволення потреб і включили новий приклад для оцінювачів, щоб вважати, що навіть якщо результат є авторитетним, якщо він не містити інформацію, яку шукає користувач, не слід оцінювати його як високу.

Я вважаю, що новий запуск Google Notes також вказує на цю причину. Google не в змозі знати зі 100% упевненістю, що є якісним вмістом.

Я вважаю, що ці події, про які я говорю, які відбулися майже одночасно, не є випадковістю і скоро ми побачимо зміни.
2. PQ (Якість сторінки)
Тут я приходжу до висновку, що вони говорять про якість сторінки, тому це моя інтерпретація. Якщо так, то в документах судового розгляду немає нічого, окрім згадки про використаний показник. Єдине офіційне, що я маю, у якому згадується PQ, це Рекомендації щодо оцінювання якості пошуку , які з часом змінюються . Отже, це було б ще одним завданням для людей-оцінювачів.

Ця інформація також надсилається в алгоритми для створення моделей. Тут ми можемо побачити пропозицію цього, що просочилася в «Project Veritas»:

Цікавий момент: згідно з документами, оцінювачі якості оцінюють лише сторінки на мобільних пристроях .

3. Пліч-о-пліч
Ймовірно, це стосується тестів, у яких два набори результатів пошуку розміщуються поруч, щоб оцінювачі могли порівняти їх відносну якість. Це допомагає визначити, який набір результатів є більш релевантним або корисним для певного пошукового запиту. Якщо так, то я пам’ятаю, що Google мав власний інструмент для завантаження, sxse .

Інструмент дозволяє користувачам голосувати за набір результатів пошуку, яким вони віддають перевагу, таким чином забезпечуючи прямий зворотний зв’язок щодо ефективності різних налаштувань або версій пошукових систем.
4. Живі експерименти
Офіційна інформація, опублікована в How Search Works, говорить, що Google проводить експерименти з реальним трафіком, щоб перевірити, як люди взаємодіють з новою функцією, перш ніж розгортати її для всіх. Вони активують функцію для невеликого відсотка користувачів і порівнюють їх поведінку з контрольною групою, яка не має цієї функції. Детальні показники взаємодії користувача з результатами пошуку включають:
- Натискає результати
- Кількість виконаних пошуків
- Залишення запиту
- Скільки часу потрібно людям, щоб натиснути результат
Ці дані допомагають визначити, чи є взаємодія з новою функцією позитивною, і гарантують, що зміни підвищать релевантність і корисність результатів пошуку.
Але судові документи висвітлюють лише два показники:

- Довгі клацання, зважені за позицією : цей показник враховуватиме тривалість клацань і їхню позицію на сторінці результатів, відображаючи задоволення користувачів результатами, які вони знаходять.
- Увага : це може означати вимірювання часу, проведеного на сторінці, що дає уявлення про те, як довго користувачі взаємодіють із результатами та їх вмістом.
Крім того, у стенограмі свідчень Панду Наяка пояснюється, що вони проводять численні тести алгоритмів із використанням чергування замість традиційних тестів A/B . Це дозволяє їм проводити швидкі та надійні експерименти, що дозволяє їм інтерпретувати коливання в рейтингу.
5. Свіжість
Актуальність є важливим аспектом як результатів, так і функцій пошуку. Важливо показувати релевантну інформацію, щойно вона стане доступною, і припинити показ вмісту, коли він застарів.
Щоб алгоритми ранжирування відображали останні документи в пошуковій видачі, системи індексування та обслуговування повинні мати можливість виявляти, індексувати та обслуговувати нові документи з дуже низькою затримкою. Хоча в ідеалі весь індекс мав би бути максимально актуальним, існують технічні та фінансові обмеження, які перешкоджають індексуванню кожного документа з низькою затримкою. Система індексування визначає пріоритетність документів на окремих шляхах, пропонуючи різні компроміси між затримкою, вартістю та якістю.
Існує ризик того, що релевантність дуже свіжого вмісту буде недооцінена, і, навпаки, контент із великою кількістю доказів релевантності стане менш релевантним через зміну значення запиту.

Роль вузла свіжості полягає в додаванні виправлень до застарілих оцінок. Для запитів, які шукають свіжий вміст, він рекламує свіжий вміст і погіршує застарілий вміст.
Нещодавно стало відомо, що Google Caffeine більше не існує (також відома як система індексування на основі Percolator). Хоча внутрішня назва все ще використовується, те, що існує зараз, насправді є абсолютно новою системою. Новий «кофеїн» фактично є набором мікросервісів, які спілкуються між собою . Це означає, що різні частини системи індексування працюють як незалежні, але взаємопов’язані служби, кожна з яких виконує певну функцію. Ця структура може запропонувати більшу гнучкість, масштабованість і легкість внесення оновлень і вдосконалень.
Як я розумію, частиною цих мікросервісів будуть Tangram і Glue, зокрема Freshness Node і Instant Glue . Я кажу це тому, що в іншому документі, який просочився з «Project Veritas», я виявив, що з 2016 року була пропозиція створити або включити « Instant Navboost » як сигнал свіжості, а також відвідування Chrome.

Наразі вони вже включили « Freshdocs-instant » (отримано зі списку pubsub під назвою freshdocs-instant-docs pubsub, куди вони брали новини, опубліковані цими ЗМІ протягом 1 хвилини після їх публікації), а також стрибки пошуку та кореляції генерації вмісту. :

Серед показників свіжості ми маємо декілька, які виявляються завдяки аналізу корельованих N-грамів і корельованих основних термінів:
- Корельовані NGrams : це групи слів, які з’являються разом у статистично значущій моделі. Кореляція може раптово збільшитися під час події чи актуальної теми, що вказує на сплеск.
- Корельовані ключові терміни: це видатні терміни, які тісно пов’язані з темою чи подією та частота появи яких зростає в документах протягом короткого періоду, що свідчить про сплеск інтересу або пов’язану з ними діяльність.
Після виявлення стрибків можна використовувати такі показники свіжості:
- Уніграми (RTW) : для кожного документа використовуються заголовок, прив’язні тексти та перші 400 символів основного тексту. Вони розбиваються на уніграми, що стосуються виявлення трендів, і додаються до індексу Hivemind . Основний текст, як правило, містить основний зміст статті, виключаючи повторювані або загальні елементи (шаблони).
- Півгодини з епохи (TEHH) : це міра часу, виражена як кількість півгодин з початку часу Unix. Це допомагає визначити, коли щось сталося з точністю до півгодини.
- Об’єкти Мережі знань (RTKG) : посилання на об’єкти в Мережі знань Google, яка є базою даних реальних об’єктів (людей, місць, речей) та їхніх взаємозв’язків. Це допомагає збагатити пошук семантичним розумінням і контекстом.
- Клітини S2 (S2) : посилання на об’єкти в Мережі знань Google, яка є базою даних реальних об’єктів (людей, місць, речей) та їхніх взаємозв’язків. Це допомагає збагатити пошук семантичним розумінням і контекстом.
- Оцінка статті Freshbox (RTF) : Це геометричні поділки поверхні Землі, які використовуються для географічної індексації на картах. Вони полегшують асоціацію веб-вмісту з точним географічним розташуванням.
- NSR документа (RTN) : Це може стосуватися релевантності документа новинам і, здається, є показником, який визначає, наскільки документ релевантний і надійний щодо поточних статей або актуальних подій. Цей показник також може допомогти відфільтрувати вміст низької якості або спаму, гарантуючи, що проіндексовані та виділені документи мають високу якість і важливі для пошуку в реальному часі.
- Географічні виміри : особливості, які визначають географічне розташування події чи теми, згаданої в документі. Вони можуть включати координати, назви місць або ідентифікатори, наприклад комірки S2.
Якщо ви працюєте в ЗМІ, ця інформація є ключовою, і я завжди включаю її в свої тренінги для цифрових редакторів.
Важливість кліків
У цьому розділі ми зосередимося на внутрішній презентації Google, надісланій в електронному листі під назвою «Unified Click Prediction» , презентації «Google is Magical» , презентації Search All Hands , внутрішньому електронному листі від Денні Саллівана та документах з « Project Veritas» витік.
Протягом цього процесу ми бачимо фундаментальну важливість кліків для розуміння поведінки/потреб користувача. Іншими словами, Google потребує наших даних. Цікаво, що однією з речей, про які Google було заборонено говорити, були кліки.

Перш ніж почати, важливо зазначити, що основні документи, які обговорюються про кліки, видані ще до 2016 року, і з того часу Google зазнав значних змін. Незважаючи на таку еволюцію, основою їхнього підходу залишається аналіз поведінки користувача, вважаючи її сигналом якості. Ви пам’ятаєте патент, де пояснюється модель CAS?

Кожен пошук і клацання, зроблені користувачами, сприяють навчанню та постійному вдосконаленню Google. Цей цикл зворотного зв’язку дозволяє Google адаптуватися та «вивчати» пошукові вподобання та поведінку, зберігаючи ілюзію, що він розуміє потреби користувачів.

Щодня Google аналізує понад мільярд нових моделей поведінки в системі, розробленій для постійного коригування та перевершення майбутніх прогнозів на основі минулих даних. Принаймні до 2016 року це перевищувало можливості систем штучного інтелекту на той час, вимагаючи ручної роботи, яку ми бачили раніше, а також коригувань, зроблених RankLab .
Наскільки я розумію, RankLab — це лабораторія, яка перевіряє різні ваги сигналів і факторів ранжирування, а також їхній подальший вплив. Вони також можуть бути відповідальними за внутрішній інструмент « Twiddler » (те, про що я також читав кілька років тому в «Project Veritas»), з метою вручну змінювати ІЧ-оцінки певних результатів , або, іншими словами, мати можливість робити все наступне:

Після цієї короткої перерви я продовжую.
У той час як рейтинги оцінювачів пропонують базове уявлення, клацання надають набагато більш детальну панораму пошукової поведінки.


Це розкриває складні закономірності та дозволяє вивчати ефекти другого та третього порядку.
- Ефекти другого порядку відображають нові закономірності: якщо більшість віддає перевагу та вибирає докладні статті, а не швидкі списки, Google це виявляє. З часом він налаштовує свої алгоритми, щоб віддавати пріоритет більш детальним статтям у пов’язаних пошуках.
- Ефекти третього порядку — це ширші, довгострокові зміни: якщо тенденції кліків сприяють вичерпним посібникам, творці контенту адаптуються. Вони починають створювати більш докладні статті та менше списків, таким чином змінюючи природу вмісту, доступного в Інтернеті.
У проаналізованих документах представлено конкретний випадок, коли релевантність результатів пошуку було покращено завдяки аналізу кліків. Google виявив розбіжність у користувальницьких уподобаннях на основі клацань щодо кількох документів, які виявилися релевантними, незважаючи на те, що вони були оточені набором із 15 000 документів, які вважаються нерелевантними. Це відкриття підкреслює важливість кліків користувачів як цінного інструменту для виявлення прихованої релевантності у великих обсягах даних.

Google «тренується з минулим, щоб передбачити майбутнє», щоб уникнути переобладнання. Завдяки постійним оцінкам та оновленню даних моделі залишаються актуальними та актуальними. Ключовим аспектом цієї стратегії є персоналізація локалізації, яка гарантує, що результати відповідають різним користувачам у різних регіонах.
Що стосується персоналізації , то в останньому документі Google стверджує, що вона обмежена й рідко змінює рейтинги. Вони також згадують , що воно ніколи не зустрічається в «Головних історіях» . Час, коли він використовується, щоб краще зрозуміти, що шукається, наприклад, використовуючи контекст попередніх пошуків, а також для створення прогнозних пропозицій за допомогою автозаповнення. Вони зазначають, що можуть трохи підвищити якість відеопровайдера, яким користувач часто користується, але всі побачать в основному однакові результати. За їх словами, запит важливіший за дані користувача.
Важливо пам’ятати, що цей підхід, орієнтований на кліки, стикається з проблемами, особливо з новим або рідкісним вмістом. Оцінка якості результатів пошуку – це складний процес, який виходить за рамки простого підрахунку кліків. Хоча цю статтю я написав уже кілька років , я думаю, що вона може допомогти глибше заглибитися в це.
Архітектура Google
Після попереднього розділу я сформував уявний образ того, як ми можемо розмістити всі ці елементи на діаграмі. Дуже ймовірно, що деякі компоненти архітектури Google не знаходяться в певних місцях або не пов’язані як такі, але я вважаю, що цього більш ніж достатньо як наближення.
Google і Chrome: боротьба за те, щоб стати пошуковою системою та браузером за умовчанням
В цьому останньому розділі ми зосереджуємося на свідченнях експерта Антоніо Рангела, поведінкового економіста та професора Каліфорнійського технологічного інституту , про використання стандартних параметрів для впливу на вибір користувачів у внутрішній презентації «Про стратегічну цінність домашньої сторінки за умовчанням для Google». , а також заяви Джима Колотороса, віце-президента Google, у внутрішній електронній пошті .
Як розповідає Джим Колотоурос у внутрішніх повідомленнях, Chrome — це не просто браузер, а ключова частина головоломки пошукового домінування Google .
Серед даних, які збирає Google, є шаблони пошуку, кліки результатів пошуку та взаємодії з різними веб-сайтами, що має вирішальне значення для вдосконалення алгоритмів Google і підвищення точності результатів пошуку та ефективності цільової реклами.
Для Антоніо Рангеля ринкова перевага Chrome перевищує його популярність. Він діє як шлюз до екосистеми Google, впливаючи на те, як користувачі отримують доступ до інформації та онлайн-сервісів. Інтеграція Chrome із Пошуком Google, яка є пошуковою системою за замовчуванням, надає Google значну перевагу в контролі потоку інформації та цифрової реклами.

Незважаючи на популярність Google, Bing не поступається пошуковій системі. Однак багато користувачів віддають перевагу Google через зручність його конфігурації за замовчуванням і пов’язані з цим когнітивні упередження . На мобільних пристроях вплив пошукових систем за умовчанням є сильнішим через тертя, пов’язані з їх зміною; для зміни пошукової системи за замовчуванням потрібно до 12 кліків.

Це налаштування за замовчуванням також впливає на рішення споживача щодо конфіденційності. Налаштування конфіденційності Google за замовчуванням створюють значні труднощі для тих, хто надає перевагу більш обмеженому збору даних. Зміна параметра за замовчуванням вимагає усвідомлення наявних альтернатив, вивчення необхідних кроків для зміни та впровадження, що викликає значні труднощі. Крім того, поведінкові упередження, такі як статус-кво та неприйняття втрат, змушують користувачів схилятися до збереження параметрів Google за умовчанням. Я пояснюю все це краще тут .
Свідчення Антоніо Рангела безпосередньо перегукуються з внутрішніми аналітичними викриттями Google. Документ показує, що налаштування домашньої сторінки браузера має значний вплив на частку ринку пошукових систем і поведінку користувачів. Зокрема, високий відсоток користувачів, які використовують Google як домашню сторінку за умовчанням, виконують на 50% більше пошуків у Google, ніж ті, хто цього не робить.

Це свідчить про сильний зв’язок між домашньою сторінкою за замовчуванням і перевагами пошукової системи. Крім того, вплив цього налаштування різниться залежно від регіону, він більш виражений у Європі, на Близькому Сході, в Африці та Латинській Америці та менш в Азіатсько-Тихоокеанському регіоні та Північній Америці. Аналіз також показує, що Google менш вразливий до змін налаштувань домашньої сторінки порівняно з такими конкурентами, як Yahoo та MSN, які можуть зазнати значних збитків, якщо втратять це налаштування.

Налаштування домашньої сторінки визначено як ключовий стратегічний інструмент Google не лише для збереження своєї частки ринку, але й як потенційна вразливість для її конкурентів. Крім того, це підкреслює, що більшість користувачів не вибирають пошукову систему активно, а схиляються до доступу за замовчуванням, наданого налаштуваннями домашньої сторінки. З економічної точки зору додаткова тривалість життя становить приблизно 3 долари США на користувача для Google, якщо він встановлений як домашня сторінка.

Висновок
Дослідивши алгоритми та внутрішню роботу Google, ми побачили важливу роль, яку кліки користувачів і оцінювачі відіграють у рейтингу результатів пошуку.
Кліки, як прямі індикатори вподобань користувачів, є важливими для Google, щоб постійно коригувати та покращувати релевантність і точність своїх відповідей. Хоча іноді вони можуть хотіти навпаки, коли цифри не збігаються…
Крім того, оцінювачі роблять важливий рівень оцінки та розуміння, що навіть в епоху штучного інтелекту залишається незамінним. Особисто я дуже здивований на цьому етапі, знаючи, що оцінювачі були важливі, але не настільки.
Поєднання цих двох вхідних даних, автоматичного зворотного зв’язку за допомогою кліків і людського контролю, дозволяє Google не тільки краще розуміти пошукові запити, але й адаптуватися до мінливих тенденцій і інформаційних потреб. У міру розвитку штучного інтелекту буде цікаво спостерігати, як Google продовжує балансувати ці елементи, щоб покращити та персоналізувати пошук у екосистемі, що постійно змінюється, з акцентом на конфіденційність.
З іншого боку, Chrome — це набагато більше, ніж браузер; це критичний компонент їх цифрового домінування. Його взаємодія з Пошуком Google і його впровадження за умовчанням у багатьох сферах впливають на ринкову динаміку та все цифрове середовище. Ми побачимо, чим закінчиться антимонопольний процес, але вони більше 10 років не сплатили близько 10 000 мільйонів євро штрафів за зловживання домінуючим становищем.
Джерело: https://www.analistaseo.es/posicionamiento-buscadores/how-google-works-working-algorithms/















